Introducing Sable-EBNF Converter
Published in Software The Sable-EBNF converter is a Windows tool that I have been working on for while to solve one particular problem: SableCC grammars are not as prolific as grammars for some other popular parser generators. SableCC is an open-source Java based context-free parser generator, capable of generating code in a number of languages (including my favourite, C#). It's grammar format is neat and quite deliberately derived from EBNF, it certainly is not EBNF itself. EBNF is a very simple format that can carry a machine- & human-readable definition of any context-free grammar. The problem is that while it is machine readable, EBNF doesn't carry enough information for the typical parser generator due to the multi-step pipeline usually employed. The other drawback of its simplicity is that there is no support for defining character ranges 1. As a result, every parser generation project has come up with its own definition of what an EBNF-styled grammar should look like with extra features to take advantage of the particular features of the project's tool. SableCC is no different. Personally I quite like SableCC because its output is very clean - by design it has no facility to allow a grammar author to insert native code into a grammar for inclusion in the generated parser, enforcing a language independent approach. SableCC has been left in a situation where fewer grammars are available to it than some other generators such as YACC/Bison and JavaCC. However many grammars in the EBNF family are available, some written in pure EBNF. And while its quite possible to hand convert these grammars to the required format, some tool support would be nice. The Sable EBNF convert aims to make conversion from EBNF and derivatives into SableCC's grammar format a faster, easier process. The tool is a Windows WPF application (.Net 4 required).
To help shape the converted grammar correctly, a few macro-operations are provided, similar to refactorings in programming. These are: Also some rudimentary editing capabilities are provided within the UI, accessed by double-clicking on an element. At this stage it supports two input formats: The Sable-EBNF converter can interface with the stock distribution of SableCC to test a converted grammar and report back any errors encountered. Error messages flagging particular elements will be attached to those elements. The SableCC grammar format frankly isn't difficult to edit as plain text. This tool is intended to be a conversion tool rather than a foundry for a whole new grammar, so the UI is oriented towards pushing existing elements around rather than creating and removing them. Though this is a work in progress it is still functional. The current version can be downloaded here.
If you need to convert grammars into a format SableCC can handle, give this a try and let me know how you go. 1: Seriously, it gets annoying when one has to define each letter of the alphabet individually as a valid piece of input for the grammar, a problem that only gets worse with Unicode. So every parser generator I have come across supports flexible character range constructs in its grammar.The goal
The tool (work in progress)
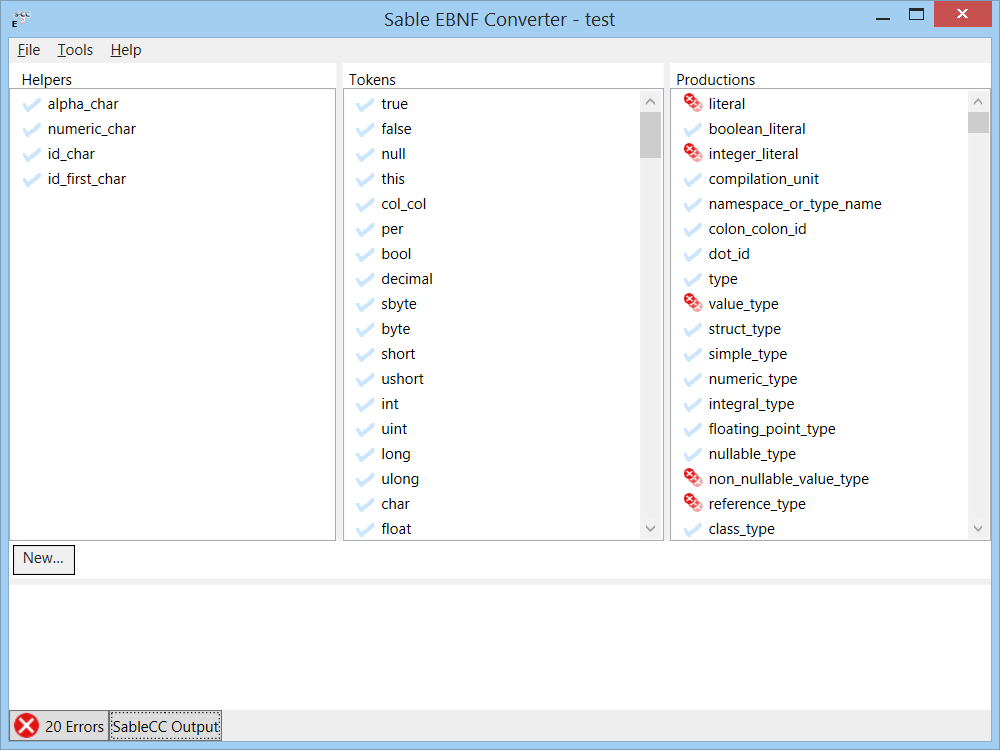 The general workflow is as follows:
The general workflow is as follows:
Supported input formats
SableCC wrapping
It's not an IDE for grammars
The to-do list
Give it a try